-
Machine Learning 실습 (4)Machine Learning 2022. 7. 13. 10:54
1. 머신러닝 과정
- 1. 문제정의 : 프젝목적, 어떤 모델만들지?, 지도학습 vs 비지도학습, 자료조사
- 2. 데이터 수집
- 3. 데이터 전처리 : 분석 전에 깔끔하게 만들어 줌(이상치 제거, 결측치 처리)
- 4. 탐색적 데이터 분석 : 컬럼(변수)간의 관계확인, 기술통계량
- 5. 모델 선택 및 학습
- 6. 모델 예측 및 평가
- 7. 모델을 가지고 서비스화(웹, 앱)
2. 목표
- 생존자/사망자 예측하는 모델을 만들어보자
- 머신러닝 모델 종류는 여러가지지만 tree모델 사용해보자
- 머신러닝 전체 과정을 체험해보자
- kaggle 경진대회에 참여해서 순위를 확인해보자
3. 데이터 수집
- kaggle 사이트로부터 train, test, submission다운로드
- train : 학습 시키기 위한 데이터
- test : 학습이 잘 됐는지 예측해보기 위한 데이터
- submission : kaggle에 제출할 답안지
import pandas as pd import numpy as np import matplotlib.pyplot as plt # 시각화 라이브러리(모듈) import seaborn as sns # 시각화 라이브러리train = pd.read_csv('./titanic/train.csv', index_col = "PassengerId") train.shape # Sibsp : 배우자 + 형제자매 수 # Parch : 부모 + 자식 수 # Cabin : 객실(층, 몇번방) # Embarked : 승선항
train.head()
# test 불러올때 승객번호 인덱스로 설정하여 불러오기 test = pd.read_csv('titanic/test.csv', index_col = "PassengerId") display(test.head()) # 본래 가지고 있는 형태를 그대로 출력 test.shape # 생존/사망 여부의 컬럼이 없어서 열의 개수가 한개 적음
4. 데이터 전처리 및 데이터 탐색
4-1. 결측치 확인
train.info() # Age, Cabin, Embarked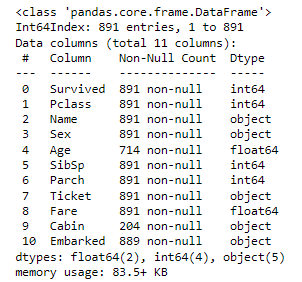
test.info() # Age, Cabin, Fare
4-2. train-Embarked 결측치 처리(채우기)
# 사람들이 가장 많이 승선한 항을 찾아 결측치 값을 처리 # train 기준으로 살펴보기 : 학습용 데이터 기준으로 살펴봐야함, 머신러닝 모델의 학습 영향을 주기때문 train['Embarked'].value_counts() # S
# 결측치가 있는 행 확인하는 작업 train[train['Embarked'].isnull()]
# 널값을 채워보자 # fillna('채울값') : 1. 결측치 찾기 2. 결측치 있으면 채우기 train['Embarked'] = train['Embarked'].fillna('S') train[train['Embarked'].isnull()]
'Machine Learning' 카테고리의 다른 글
Machine Learning 실습 (6) (0) 2022.07.13 Machine Learning 실습 (5) (0) 2022.07.13 Machine Learning 실습 (3) (0) 2022.07.12 Machine Learning 실습 (2) (0) 2022.07.12 Machine Learning 실습 (1) (0) 2022.07.12